




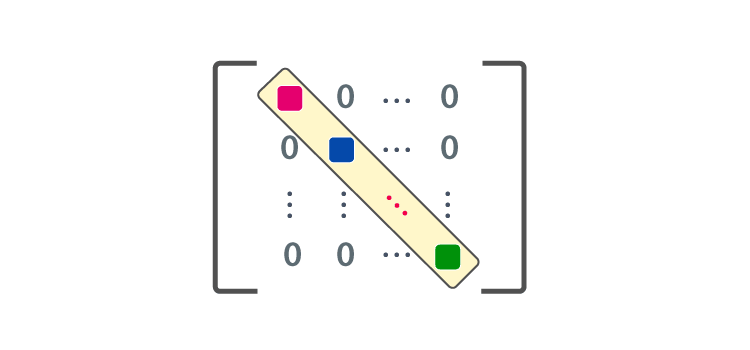
A matrix is said to be diagonal if all its non-diagonal elements are zero. In other words, a diagonal matrix is a square matrix where all the elements outside the main diagonal are zero.
The main diagonal of a matrix is the set of elements that runs from the top-left corner to the bottom-right corner of the matrix. For example, in a 3×3 matrix, the main diagonal includes the elements (1,1), (2,2), and (3,3).
A diagonal matrix can be represented compactly by listing its diagonal elements in a single row or column vector. For example, the diagonal matrix with diagonal elements 2, 4, and 6 can be represented as:
csharp
[2 0 0]
[0 4 0]
[0 0 6]
Diagonal matrices have several important properties that make them useful in various mathematical applications. For example, diagonal matrices are easy to invert, and the product of two diagonal matrices is another diagonal matrix whose diagonal elements are the product of the corresponding elements of the original matrices. Additionally, diagonal matrices are useful for solving systems of linear equations and for performing eigenvalue and eigenvector calculations.
Diagonal matrix
In linear algebra, a diagonal matrix is a matrix in which the entries outside the main diagonal are all zero; the term usually refers to square matrices. Elements of the main diagonal can either be zero or nonzero. An example of a 2×2 diagonal matrix is

![{\displaystyle \left[{\begin{smallmatrix}3&0\\0&2\end{smallmatrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbd1681ed0048aa1b28a2e9b5f6bb834b1cc3b14)

![{\displaystyle \left[{\begin{smallmatrix}6&0&0\\0&0&0\\0&0&0\end{smallmatrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/102b26daf8bf17c5c32fd64d3d899d9e012d5127)
A diagonal matrix is sometimes called a scaling matrix, since matrix multiplication with it results in changing scale (size). Its determinant is the product of its diagonal values.
Main diagonal
In linear algebra, the main diagonal (sometimes principal diagonal, primary diagonal, leading diagonal, major diagonal, or good diagonal) of a matrix








Diagonalizable matrix
In direct variable based math, a square lattice is called diagonalizable or non-flawed assuming it is like a corner to corner framework, i.e., on the off chance that there exists an invertible grid and a slanting network with the end goal that , or equally . (Such , are not novel.) For a limited layered vector space , a direct guide is called diagonalizable on the off chance that there exists an arranged premise of comprising of eigenvectors of . These definitions are same: in the event that has a lattice portrayal as over, the section vectors of structure a premise comprising of eigenvectors of , and the corner to corner passages of are the comparing eigenvalues of ; regarding this eigenvector premise, is addressed by . Diagonalization is the most common way of seeing as the abovementioned and .
Diagonalizable frameworks and guides are particularly simple for calculations, when their eigenvalues and eigenvectors are known. One can raise a slanting network to a power by basically raising the corner to corner sections to that power, and the determinant of an inclining grid is just the result of every slanting passage; such calculations sum up effectively to . Mathematically, a diagonalizable network is an inhomogeneous expansion (or anisotropic scaling) — it scales the space, as does a homogeneous widening, however by an alternate element along each eigenvector pivot, the component given by the relating eigenvalue.
A square lattice that isn’t diagonalizable is called flawed. It can happen that a grid with genuine passages is faulty over the genuine numbers, implying that is unimaginable for any invertible and inclining with genuine sections, however it is conceivable with complex sections, so that is diagonalizable over the perplexing numbers. For instance, this is the situation for a conventional pivot framework.
Many outcomes for diagonalizable lattices hold just over a mathematically shut field (like the intricate numbers). For this situation, diagonalizable grids are thick in the space of all lattices, and that implies any deficient framework can be disfigured into a diagonalizable network by a little irritation; and the Jordan ordinary structure hypothesis expresses that any grid is extraordinarily the amount of a diagonalizable framework and a nilpotent framework. Over a mathematically shut field, diagonalizable frameworks are identical to semi-basic grids.
Diagonal

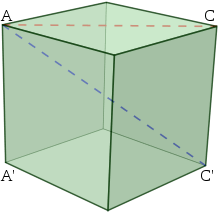
In calculation, a corner to corner is a line section joining two vertices of a polygon or polyhedron, when those vertices are not on a similar edge. Casually, any inclining line is called askew. The word inclining gets from the old Greek διαγώνιος diagonios, “from one point to another” (from διά-dia-, “through”, “across” and γωνία gonia, “point”, connected with gony “knee”); it was utilized by both Strabo and Euclid to allude to a line interfacing two vertices of a rhombus or cuboid, and later embraced into Latin as diagonus (“inclining line”).
In grid variable based math, the slanting of a square lattice comprises of the passages on the line from the upper passed on corner to the base right corner.
There are additionally other, non-numerical purposes.
Tridiagonal matrix
In straight polynomial math, a tridiagonal framework is a band lattice that has nonzero components just on the primary slanting, the subdiagonal/lower corner to corner (the principal inclining underneath this), and the supradiagonal/upper askew (the principal slanting over the fundamental corner to corner). For instance, the accompanying framework is tridiagonal:

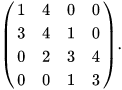
The determinant of a tridiagonal network is given by the continuant of its components.
A symmetrical change of a symmetric (or Hermitian) network to tridiagonal structure should be possible with the Lanczos calculation.
White paper on Diagonal
Here’s an overview of what a white paper on diagonal matrices might cover:
- Introduction: An overview of what diagonal matrices are and why they are important in various mathematical applications.
- Definition and Properties: A detailed definition of diagonal matrices and their properties, including the relationship between diagonal matrices and scalar multiplication, addition, and inversion.
- Applications: Examples of how diagonal matrices are used in various mathematical applications, such as solving systems of linear equations, computing eigenvalues and eigenvectors, and representing linear transformations.
- Algorithms: Descriptions of algorithms for working with diagonal matrices, including algorithms for diagonalizing a matrix and computing the product of two diagonal matrices.
- Comparisons to Other Matrix Types: Comparisons between diagonal matrices and other matrix types, such as symmetric matrices, Hermitian matrices, and unitary matrices.
- Extensions and Variations: Discussions of extensions and variations of diagonal matrices, such as block diagonal matrices, tridiagonal matrices, and diagonalizable matrices.
- Conclusion: A summary of the main points covered in the white paper and a discussion of future directions for research on diagonal matrices.
Overall, a white paper on diagonal matrices would provide a comprehensive overview of this important mathematical concept and its applications, including both theoretical and practical considerations.